在你生日那天哈勃望远镜看到了什么
为庆祝哈勃空间望远镜发射30周年,NASA推出了一个网站,往里输入自己的生日,系统将返回某年同一天哈勃望远镜拍摄的太空照。
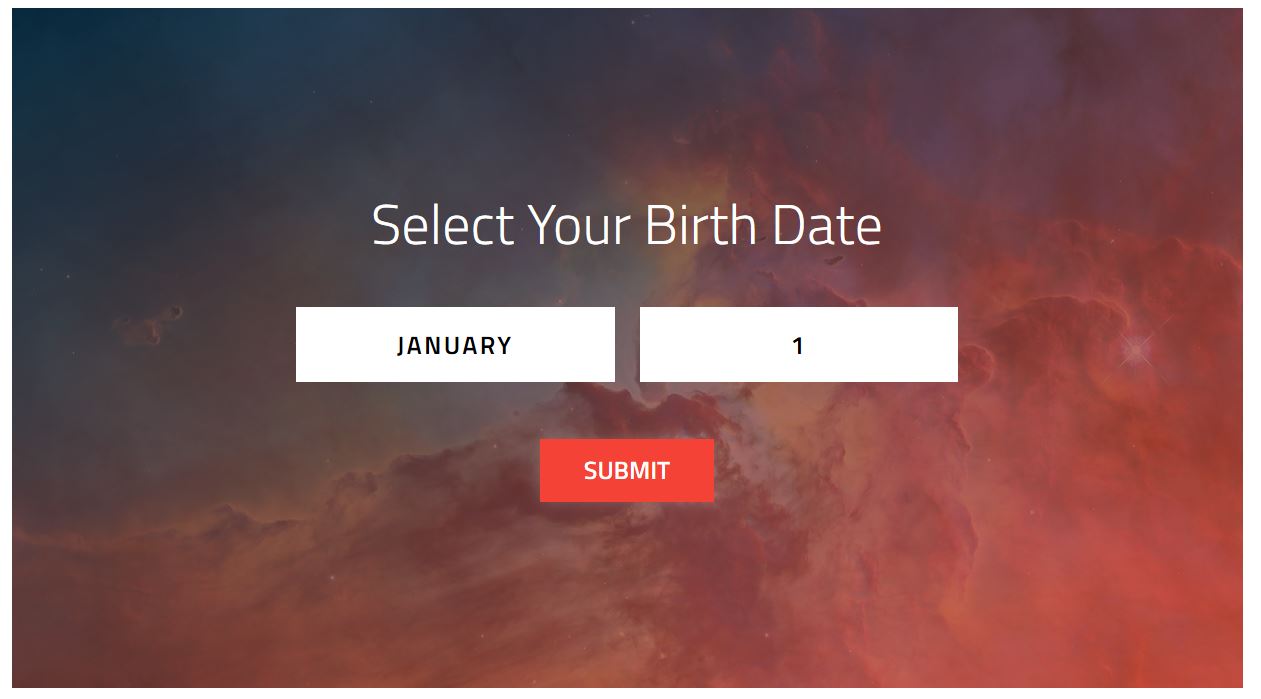
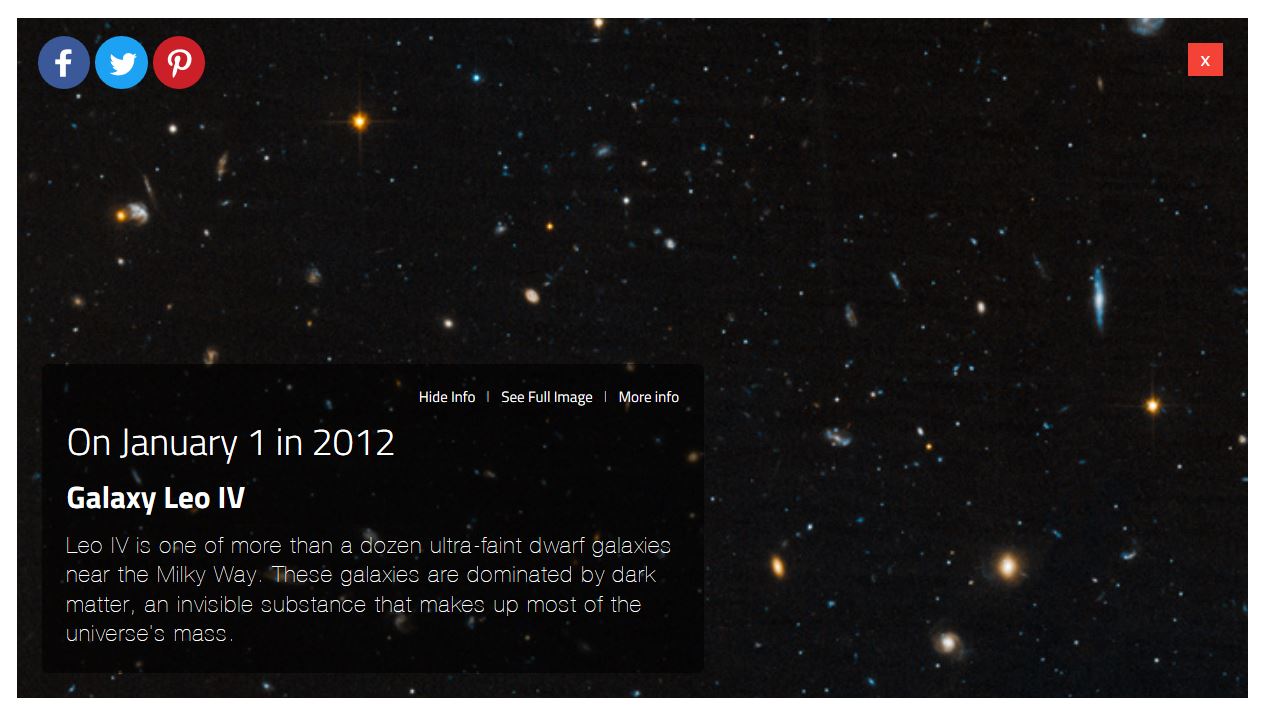
很“自然”,我就想把一年所有的照片都下载下来。
我们当然可以逐个输入日期然后点击「See Full Image」来查看大图,最后保存相应的图片。不过在我这里打开网页很慢,快的一次操作下来30秒,慢的一分钟都打不开,按平均45秒算,我们就得连续操作将近5个小时……我怀疑不用十分钟我的热情就会被消耗殆尽了。
前期准备
可以尝试下写个爬虫程序自动获取图片。
为了获取不同日期的图片,我们首先需要知道每张图片的地址。我们先看下不同日期的图片是否有什么规律。比如1月1日图片的地址是 https://hubblesite.org/uploads/image_file/image_attachment/23369/xlarge_web.jpg,1月2日图片的地址是 https://hubblesite.org/uploads/image_file/image_attachment/13605/xlarge_web.jpg,而1月3日图片的地址是 https://hubblesite.org/uploads/image_file/image_attachment/30030/STSCI-H-p-1714a-m-1727x2000.png,没有什么明显的规律,看起来更像是有个图片->地址的对应表。
{kind=link}
{kind=link}
{kind=link}
再仔细查看页面下方一行字「A text version is available for screen readers.」,点击「text version」将会下载一个Excel表格(hubble-birthdays-full-year.xlsx),里面含有每张图片的拍摄日期和年份、图片名、图片说明以及一个链接。该链接是否就是图片的链接呢?很遗憾,该链接不会直接指向图片,而是更为详尽的图片说明。不过图片说明页的左侧有一下载选项,可以下载不同大小的图片。所以,这里有一个思路,我们可以加载 hubble-birthdays-full-year.xlsx,读取每一行链接,加载相应页面,读取下载选项中不同图片大小的地址,就可以下载了。不过这里的图片跟生日页面的大图好像有点不大一样。这个思路暂且作罢。
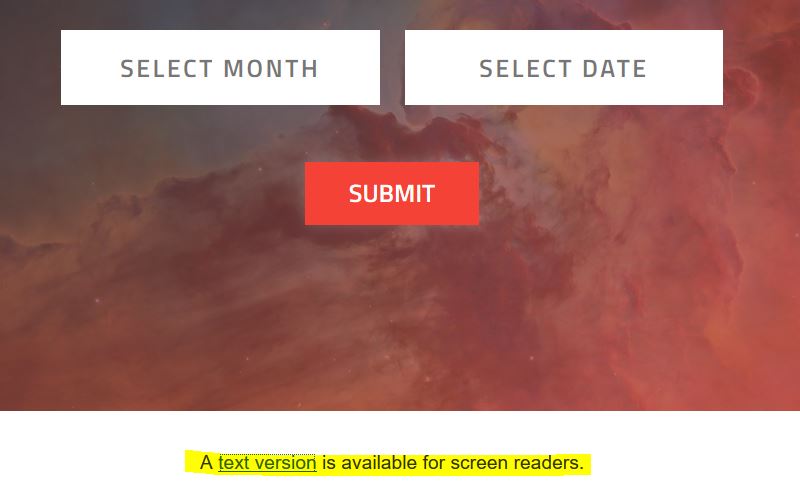
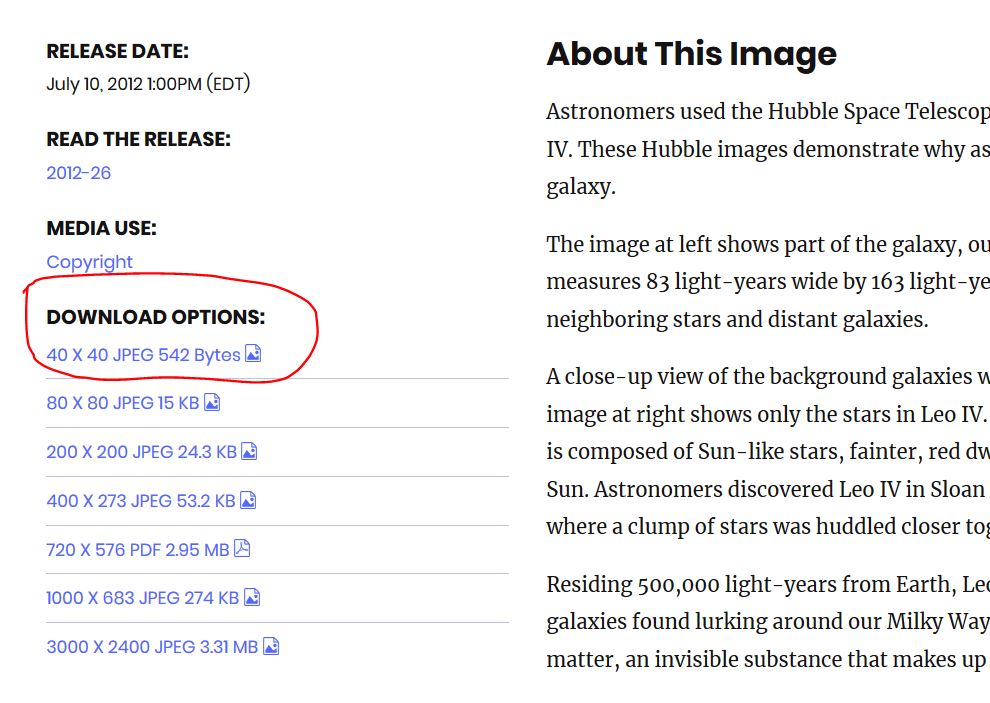
回到生日页面,我们用网络开发工具查看页面加载了什么内容。在 Firefox 里面打开 Web developer - Network(Chrome 和 Edge 中类似),然后选个生日点击Submit,可以看到如下内容:
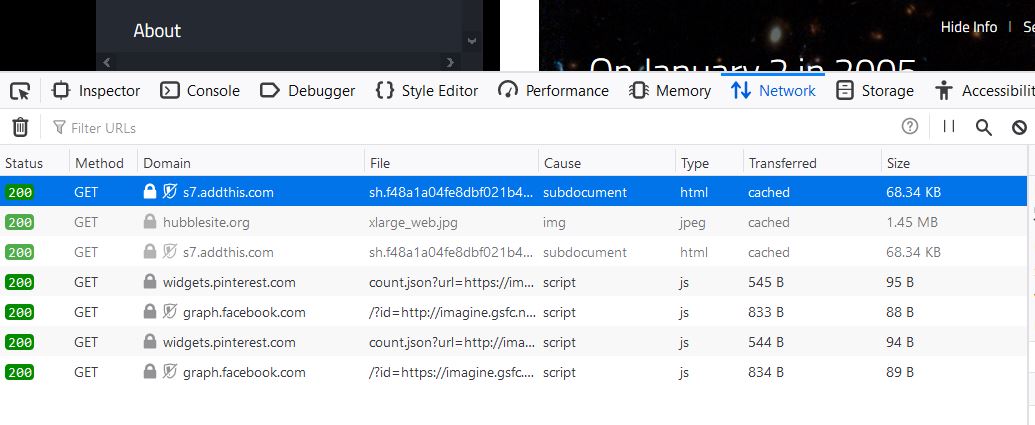
好像没什么新的内容。
我们刷新一下页面:

「乱军丛中」,我们会发现页面会加载一个 data.csv 的文件, 具体地址为https://imagine.gsfc.nasa.gov/hst_bday/data.csv,点击下载下来看一下,Tada, 正是我们要找的。其中文档第一列为日期,第二列就是具体大图的地址了。后续自然就好办了。

Mathematica
一开始我想用Mathematica试一下。
先清理所有的整理变量,并设置笔记本目录为工作目录:
ClearAll["Global`*"]
SetDirectory[NotebookDirectory[]]
创建 pictures 目录,用于存放所有的图片:
CreateDirectory["pictures"];
加载 data.csv 的数据,我们只要前两列和最后一列(分别对应日期、链接和拍摄年份),并且去掉第一行:
data = Import["data.csv", "Data"][[2 ;; -1, {1, 2, 6}]];
创建函数 export,其将接受日期 date 、链接 url (均为字符串)以及拍摄年份 year (整数) ,然后下载相应图片,如果下载失败,则输出该失败条目的 date 、 url 和 year,具体将实现如下内容:
-
确定输出图片的格式。我们发现图片有的格式为
jpg,有的为png,具体根据url的最后部分就可以确定:figformat = StringCases[url, __ ~~ "/" ~~ __ ~~ "." ~~ x__ -> x]; -
确定图片的名称。图片就以日期和拍摄年份命名,因为
data.csv的日期为「January 1 2019」的形式,因此需把 2019 替换掉:trimdate = StringReplace[date, "2019" -> ToString[year]]; -
输出的文件名就为名字加格式了:
outname = FileNameJoin[{"pictures", trimdate <> "." <> figformat}]; -
使用
URLDownload下载图片到指定文件:status = URLDownload[url, outname, "StatusCode"];这里我们也可以尝试用
Export[outname,Import[url]]不过
Import会压缩图片(但查看了下分辨率并无变化……) -
最好还记录下下载的情况,如果成功,不作处理,如果不成功,将此下载信息存起来,以备后续再下载。这里用
fail实现:如果成果,fail=Nothing,如果失败,fail={date,url,year}。不过有个问题:不是很清楚URLDownload和Import下载失败返回的代码……
最后将 export 函数分别应用到 data 每一行即可。
NestWhile[ParallelMap[export[#[[1]], #[[2]], #[[3]]] &, #] &, data,
Length[#] > 0 &]
全部遍历后,将会重新下载之前失败的条目,直到所有都成功下载了。Map 用了并行,以期加快下载速度。
总的代码大概如下:
ClearAll["Global`*"]
SetDirectory[NotebookDirectory[]]
CreateDirectory["pictures"];
data = Import["data.csv", "Data"][[2 ;; -1, 1 ;; 2]];
export[date_String, url_String, year_Integer] := Module[
{figformat, trimdate, fig, outname, fail},
figformat = StringCases[url, __ ~~ "/" ~~ __ ~~ "." ~~ x__ -> x];
trimdate = StringReplace[date, "2019" -> ToString[year]];
outname = FileNameJoin[{"pictures", trimdate <> "." <> figformat}];
Print["Downloading " <> trimdate <> " ..."];
fig = Import[url];
fail = Nothing;
If[FailureQ[fig], (*may not work*)
Print["Failed to download " <> trimdate];
fail = {date, url, year},
Export[outname, fig];
Print["Successfully downloaded " <> trimdate]
];
fail
]
NestWhile[
ParallelMap[export[#[[1]], #[[2]]] &, #] &, data[[3 ;; -1]],
Length[Flatten[#]] > 0 &]
效果如何呢?
再次遗憾,如此耍弄一通后,下载结果很感人:速度非——常——慢!下载失败的概率很高,上述代码还不能很好处理失败的情况。还有一个问题,代码显示下载成功了,但是打开图片后发现并不完整。
所以还得另找更合适的方式。
Aria2c
重新梳理下现在我们想做什么:我们有一系列图片的链接,我们希望将其都下载下来,并且根据一定的规则重新命名该图片。
非常幸运,就是有这样的神器:Aria2。
Aria2 可以视作增强版的 wget,可以通过输入文件多线程下载多个文件。针对我们的例子,Aria2的用法如下:
aria2c -c --dir=pictures --max-concurrent-downloads=5 --max-connection-per-server=3 --input-file=download-list.txt --save-session=hubble30.session
其中相关选项为:-c :断点下载;--dir:设定文件保存的目录;--max-concurrent-downloads:同时下载的最大数目;--max-connection-per-server:每台服务器的最大连接数;--input-file:指定下载链接的文件;--save-session:将记录失败条目,可以下次作为input-file 继续下载。为了减少服务器的压力,同时连接数和下载数还是设小一点。
最关键的输入文件download-list.txt 的格式如下:
https://hubblesite.org/uploads/image_file/image_attachment/23369/xlarge_web.jpg
out=January 1 2012.jpg
https://hubblesite.org/uploads/image_file/image_attachment/13605/xlarge_web.jpg
out=January 2 2005.jpg
https://hubblesite.org/uploads/image_file/image_attachment/30030/STSCI-H-p-1714a-m-1727x2000.png
out=January 3 2017.png
一条链接一行(也可以一行里多条链接用空格或tab隔开),紧接的新行为该下载链接的选项,比如这里对应每条链接,我们将其输出文件通过out 重命名。注意每行只能一个选项,并且选项前要有空格,比如这里out 前有空格。
我们可以用 Mathematica 快速生成上述文件:
writeToAria2File[date_String, url_String, year_Integer] := Module[
{figformat, changeyear, outname},
figformat = StringCases[url, __ ~~ "/" ~~ __ ~~ "." ~~ x__ -> x];
changeyear = StringReplace[date, "2019" -> ToString[year]];
outname = changeyear <> "." <> figformat;
url <> "\n" <> " out=" <> outname
]
writeToAria2File[#1, #2, #3] & @@@ data //
Export["download-list.txt", #] &
好了,可以慢慢欣赏美图了。
2021.05.20 补充
S1 论坛上有人求批量下载图片,要求如下:
求人下载图片 一共是64*96=6144张
下载好的 0.jpg之类的1位数能改成00这样的标准2位文件名吗
最好按照00 ~63作为文件夹 每个文件夹00~95 一共96个图片
下载地址规律如下
https://s.rsg.sc/sc/images/games/GTAV/map/print/7/0/0.jpg … https://s.rsg.sc/sc/images/games/GTAV/map/print/7/0/95.jpg
https://s.rsg.sc/sc/images/games/GTAV/map/print/7/1/0.jpg … https://s.rsg.sc/sc/images/games/GTAV/map/print/7/1/95.jpg
… …
https://s.rsg.sc/sc/images/games/GTAV/map/print/7/62/0.jpg … https://s.rsg.sc/sc/images/games/GTAV/map/print/7/62/95.jpg
https://s.rsg.sc/sc/images/games/GTAV/map/print/7/63/0.jpg … https://s.rsg.sc/sc/images/games/GTAV/map/print/7/63/95.jpg
显然比上面简单多了,Shell 代码如下:
#!/bin/bash
FILE="download-list.txt"
SESSIONFILE="sample.session"
DIRNUM=63
IMGNUM=95
rm $FILE
# To generate download input file for aria2
for i in $(seq 0 $DIRNUM)
do
for j in $(seq 0 $IMGNUM)
do
printf "https://s.rsg.sc/sc/images/games/GTAV/map/print/7/$i/$j.jpg\n" >> $FILE
printf " dir=%02d\n out=%02d.jpg\n" $i $j >> $FILE
done
done
aria2c -c --dir=pictures --max-concurrent-downloads=5 --max-connection-per-server=3 --input-file=$FILE --save-session=$SESSIONFILE